
Base64를 사용하는 이유
Posted 2024.12.27 09:00
By recoma
개요
회사에서 개발과 관련된 일을 하다 보면 OpenAPI를 이용한 기능을 구현할 때가 있다. 그런데 간혹 공공기관의 OpenAPI를 이용하다 보면 대부분 인증 관련 데이터를 Base64로 인코딩을 해달라는 요구가 있다. 심지어 운전면허 검증 API중의 하나인 RIMS API의 경우 body 마저도 AES 암호화에 Base64까지 인코딩을 해야 한다. 아니 어차피 HTTPS로 암호화를 따로 할 텐데 왜 도대체 이런 짓들을 하는 걸까? Base64의 의미와 사용하는 이유를 알아보자.
Base64
설명
Base64란 바이너리 데이터를 문자로 64진법 형식으로 인코딩을 하는 방식을 말한다.
| M | a | n |
|---|---|---|
| 01001101 | 01100001 | 01101110 |
예를 들어 “Man”을 Base64로 인코딩한다고 하자, 문자(char)의 데이터 크기는 1byte, 즉 8bit이다. Man이라는 문자열의 길이는 총 3byte이므로 8bit + 8bit + 8bit = 24bit이다. Base64는 이걸 64진법으로 인코딩한다고 했는데. 64는 2^6이다. 즉, 24bit를 6bit 단위로 쪼갠 다음, Base64 색인표에 따라 텍스트를 생성한다.
출처: 위키백과
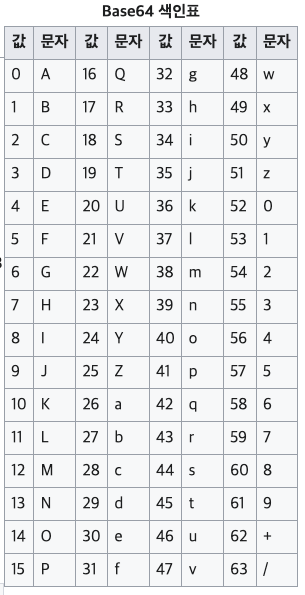
| T | W | F | u |
|---|---|---|---|
| 010011 | 010110 | 000101 | 101110 |
이렇게 해서 “Man”에서 “TWFu”로 인코딩이 되었다.
마지막을 =로 패딩하는 이유
가끔씩 보면 마지막이 “=”로 끝나는 경우가 있다. 8bit단위에서 6bit단위로 쪼개기 때문에 마지막에 2bit 혹은 4bit가 비게 되는데. 이때는 “=” 기호로 padding을 하게 된다. 예를 들어 hello world를 base64로 인코딩을 하면 aGVsbG8gd29ybGQ= 로 나온다. hello world라는 문자의 길이는 11byte = 88bit이고 이를 6bit로 쪼개면 마지막에 2bit가 비게 되는데, 이 2bit를 대신 =로 채운 것이다.
단점
아까 보다시피 “Man”에서 “TWFu”로 인코딩이 되었는데, 3글자에서 4글자로 1글자 더 추가되었다. 비트를 쪼개는 단위가 8bit에서 6bit로 줄면서 그만큼 글자가 늘어났기 때문이다. 즉, Base64 방식은 데이터의 길이가 늘어난다는 단점이 생기게 된다. 데이터가 커질 수록 스토리지에 저장한다던가, 아니면 데이터 통신을 하는데 있어서 상대적으로 부담이 커질 수 밖에 없다. 그럼에도 불구하고 왜 자주 사용을 할까?
사용 이유
바이너리 데이터를 손실없이 전송할 수 있기 때문이다. 데이터 중에서는 우리가 알아볼 수 있는 문자 데이터 말고도 바이너리 데이터에 해당되는 그림 파일, 동영상 파일 등이 있다. 이러한 바이너리 데이터들중 일부는 ASCII 코드에 해당하지 않는 경우가 있다. 그 이유는 문자(char)의 길이는 8bit(1byte)이지만, ASCII의 범위는 0부터 127까지로 7bit이기 때문이다. 즉, 128부터 255 까지는 ASCII 코드에 해당하지 않기 때문에, 수신자는 이 데이터들을 해석하지 못하게 된다. 하지만 Base64 인코딩을 사용해 바이너리 데이터들을 ASCII형태의 문자열로 변환을 하게 된다면, 수산자는 해당 데이터를 바로 해석을 할 수 있고, 그 이후에 Base64를 포함한 후속 작업을 진행할 수 있게 된다.
예시: 이메일 전송시 사용
이러한 대표적인 예로 메일을 주고받을 때 사용되는 STMP 프로토콜이 있다. 이 프로토콜은 7bit 단위의 데이터만 취급하기 때문에 8bit 이상의 유니코드나, 기타 바이너리 데이터들은 Base64로 6bit 단위로 인코딩을 해서 송수신을 한다.
UTF-8 과의 차이점
찬혹 UTF-8 인코딩과 헷갈릴 수 있는데 UTF-8은 Unicode Transformation Format - 8bit 의 약자다. 즉, 유니코드를 표현하기 위해 사용되는 인코딩 방식으로, 다양한 언어를 표현할 때 사용된다. 안전성을 목적으로 둔 Base64와는 경우가 다르다.
파이썬에서 Base64 사용해 보기 (feat. UTF-8)
파이썬에서는 base64로 인코딩 또는 디코딩을 하는 모듈을 기본으로 제공한다.
인코딩
import base64
text = '안녕 월드'
utf_text = text.encode('utf-8')
print(utf_text)
# 바이너리로 변환 -> b'\xec\x95\x88\xeb\x85\x95 \xec\x9b\x94\xeb\x93\x9c'
encoded_text = base64.b64encode(utf_text)
print(encoded_text)
# b'7JWI64WVIOyblOuTnA=='
디코딩
import base64
encoded_text = b'7JWI64WVIOyblOuTnA=='
decoded_text = base64.b64decode(encoded_text)
# base64 디코딩 -> b'\xec\x95\x88\xeb\x85\x95 \xec\x9b\x94\xeb\x93\x9c'
text = decoded_text.decode('utf-8')
print(text)
# utf-8 디코딩 -> 안녕 월드